Optimizing BankforMAP
Optimizing a parallel application by removing parallelism
Written by Owen Parkins
Published December 2023
Modified March 2024
| What is BankforMAP?
BankforMAP is an environmental assessment application designed to run another library called BankforNET over an entire stream.
As posted by ecorisQ:
BankforNET is an online tool that simulates hydraulic streambank erosion that can be expected in relation to the channel morphology, bank material, vegetation roots and the discharge scenario. It is a is a one-dimensional, probabilistic model which applies randomness to the soil erosion parameters. The model uses an empirical excess shear stress equation, where the effects of roots are implemented by adapting the material dependent critical shear stress to consider the spatio-temporal distribution of root area ratio (RAR), the dynamics of channel geometry, and stream discharge (cf. Gasser et al., 2020). This tool aims to support experts in the quantification of bank erosion hazards and the effects of biological measures.
Simplified, BankforMAP finds a stream, computes the required input values for BankforNET, runs BankforNET, and then does some additional computations. The input for BankforMAP is a raster file. This raster file can be simplified to a matrix where x/y are locations in the real world and the value at those x/y coordinates can be environmental data collected from location surveys.
| Why Optimze?
We need to optimize this application because end users are not able to process larger streams on their own devices. It is normal that some streams require larger servers to process, but we reached a threshold where even smaller streams were not able to be processed on laptops and work devices.
We began to investigate where our efficiency issues began and many of the issues start with the original design.
Original Design
As often happens with many developing applications, scope creep occurred; Too many changes were requested that required fundamental changes to the application. The original design was to process each cell at these x/y coordinates independently because no cell was dependent on another. Eventually a feature was requested to follow a stream. This meant at some point in the calculations the application had to follow a specific processing order. We merged these two processing methods because the application was still being developed and it wasn't worth refactoring yet.
Consequences
We got to a point where processing large rasters was infeasible by normal machines. It was slow and inefficiently used memory. Our core issues stemmed from:
raster class loads the entire raster into memory, including nodata values.- This means that if we have fairly empty rasters, we are using the same amount of memory to store empty rasters as if they all had valid data. This problem is made worse because many different rasters are used to provide output data.
- This recursive function ran into limitations due to the stack depth that was possible.
- Since each cell was processed separately, this meant a lot of redundant processing was occurring. It is clear that neighboring cells could share information to help find the upstream and downstream cells faster.
- Many design choices were due to an understanding that it would be a CLI application only. But this requirement changed which showed the original design choices weren't adequate. For instance, we were printing to the console by default, lacked proper modularity for library integration, and more.
We knew to fix these issues a core refactor would have to occur.
| How to Optimize?
Knowing the issues above, we had three main goals:
- More efficiently process the raster (less CPU cycles total)
- More efficient memory usage
- Design to be more modular and withstand new requirements
Getting The Numbers
First, we had to know what to optimize. We did this with callgrind:
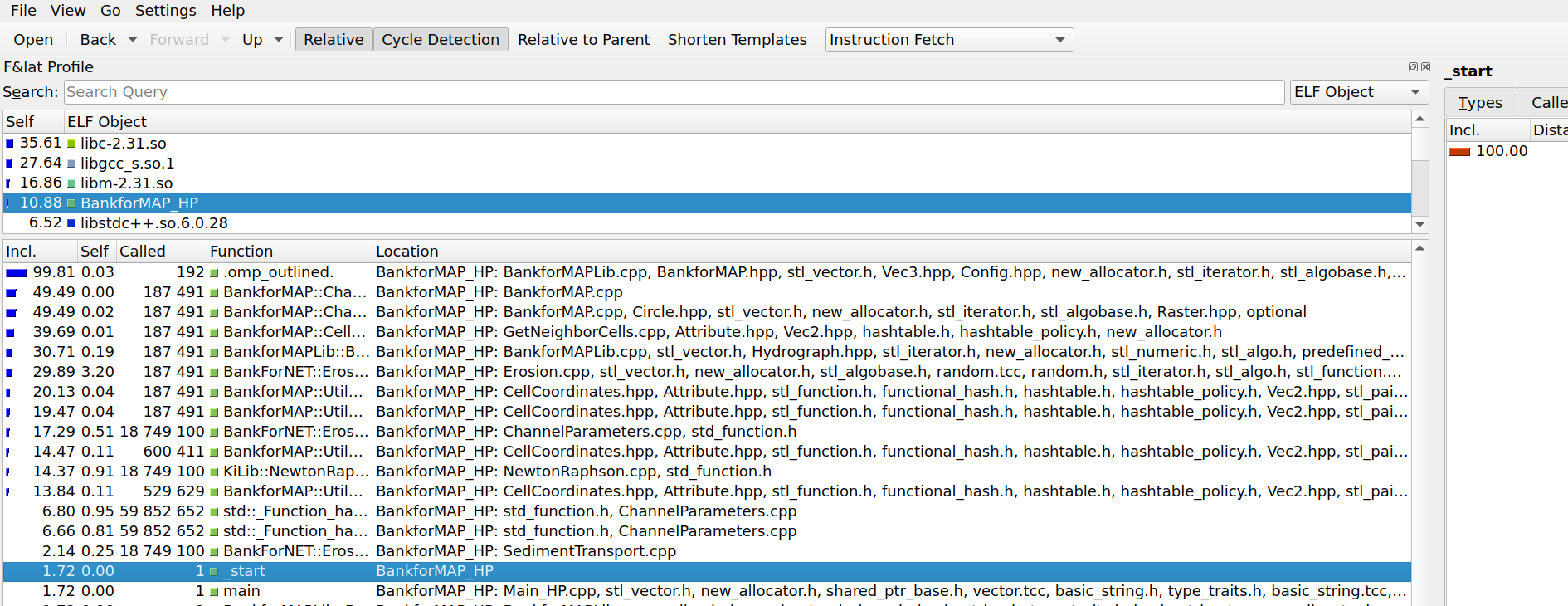
While the code for BankforMAP isn't publicly available, it is evident that there is a lot going on. There is a lot of time spent getting neighbor cells and creating bounds and as a result, there is room for improvement.
New Design
The new design aimed to reduce complexity, increase modularity, and remove parallalism from the code:
- Due to the changing requirements, different workflows had to be created. We removed these built-in workflows and opted for a pipeline design. This simplified the inputs/outputs for each piece.
- There is a clear distinction between CLI and library now. This ensures future integrations are less painful.
- Each calculation that has to be run for a cell is now an object called a processor. All associated information with that calculation is contained. This means we can have multiple ways to calculate the same value without modifying existing code.
- No print statements are found in the library. Only function calls that can be used by calling applications.
- Multiple types of rasters can now be used. We have implemented Sparse rasters to help with our memory consumption issues.
- Instead of processing each cell separately, we now use knowledge gained from an upstream calculation to significantly reduce the time it takes to determine upstream and downstream cells. We are tracking the stream now.
| Results
Was it worth it?
Absolutely. We are able to run large problems on personal machines while preparing for future requirements. Each time a new requirement is added, we have the option of either adding the feature into the existing CLI, or quickly creating a new CLI that extends the functionality for a specific purpose. If calculations are updated or changed we don't have to reintegrate new ideas into the application due to the modularity that is now available.
We also have the option of running this within WebAssembly. This means we run untrusted user input in an isolated environment without overhead. This means customers can now process even larger grids.
Overall, we look forward to seeing what this new version of BankforMAP enables us to do.